Data analysis has always had a clear end goal: dashboards. People understand information better through visuals. A good dashboard tells you in seconds what would take hours to figure out from raw data. But getting to that dashboard? That's where things get complicated.
The path from data to insights is messy for several reasons. First, you need deep domain expertise. Finance people don't just see numbers—they see liquidity ratios, covenant breaches, cash flow patterns. Marketing analysts see conversion funnels, customer segments, attribution models. Every field has developed its own way of thinking about data over decades. These aren't just different charts—they're fundamentally different analytical frameworks.
Second, human bias creeps in. When you've presented quarterly results a hundred times, you develop habits. You know which metrics to emphasize, which comparisons to make, which visualizations tell your preferred story. It's not dishonest—it's human nature. We all fall into patterns that shape how we present information to stakeholders.
Third, the interfaces are complex. Excel, Power BI, Tableau—all require working through layers of interfaces, menus, formulas, and configurations. The complexity exists because the tools were built before the day that we could readily describe what we wanted in natural language.
LLMs promise to do away with all of this. Natural language to insights. Ask questions, receive answers. And they can be beneficial, but hardly the easy way one might imagine.
What LLMs Don't Understand (And Where They Go Wrong)
Generic LLMs do have one hard limitation: they don't possess domain-specific intuition. They can't automatically reproduce the mental models of how a financial analyst intuitively thinks about data compared to a marketing analyst. The esoteric knowledge that distinguishes each field—the things that the experts recognize on the spot, the things that they know to ask, the things that induce different modes of interpretation—is difficult to incorporate in a general-purpose model.
Then the plot thickens. That absence of learned experience? That too is strength. The LLM carries no narrative agenda that it wishes to impose. The machine will not, of course, suppress the discouraging metric or stress the comparison that makes metrics appear better. The machine carries no narrative that it wishes to spread. It carries no agenda beyond what the data offers or queries to be posed.
That is the trade-off: the absence of domain knowledge in the LLMs, balanced with the absence of human bias. They are incapable of replacing the analyst who has the business context, but incapable as well of unconsciously framing the analysis to lead to a foregone conclusion. So the issue becomes how to achieve the advantages with the management of the constraints?
The Solution: Let Them Write Code
We've had the pleasure of working with LLMs for some time now, and one thing is certain: they are very adept at producing code. Of course, whatever they produce in textual form is about as templated as can be—advanced copy-paste from the learning set. However, with code, templated or otherwise doesn't matter as long as the code functions. And function it does. The proof is in the pudding: the largest consumers of the LLMs are the coders. They aren't playing with the LLMs as toys—they are invaluable tools within their day-to-day workload.
This tells us something fundamental about how LLMs should work. Code becomes their limbs, their way of actually doing things instead of just describing them. When we build systems with LLMs, we need to use their coding ability as the foundation. That's where their real strength is.
Think about why this is so powerful. When we speak or write natural language, we are really trying to find patterns within the world and cram them into words. Language is interpretation, approximation. Code is different. Code is mathematical, more precise. Code doesn't outline a calculation—it is the calculation. Code doesn't approximate a procedure—it specifies it exactly.
The LLMs are trained on vast quantities of code, text, and data. However, as they produce code, they are doing what best suits the nature of the territory. They are pattern-matching machines being asked to generate the kind of patterns that other machines run. There is a directness to this that doesn't happen as they are asked to do things with the data directly.
This completely revolutionizes all of what we should be doing in data analysis with LLMs. The wrong way is to give them massive datasets and to ask them to recognize the pattern instantly. The right way is to give them the ability to write programs—and to allow the program to find the pattern. Don't ask the LLM to find the pattern. Ask it to produce the program that will exhibit the pattern.
When the LLM produces SQL or Python to look at data, that is code that can be read and checked by people. The code is the method the LLM applies to data to transform it, and that cuts hallucination way back. The model is no longer faking that it can recognize patterns—it is specifying how to look for them.
SQL is especially ideal for this. It was made to scale to big data. When an LLM produces SQL, it is drawing on years of experience in minimizing database operation costs. The language itself constrains the model towards correct operations, towards queries that will execute successfully and give actual results.
The Collaborative Approach
The idea is that the ideal use of LLMs is as augmenters, but not autopilots. Automated data analysis is a nice dream—you pose the question, you receive the answer, no human required. That is where the true value is lacking. The value is in augmentation, but certainly not automation.
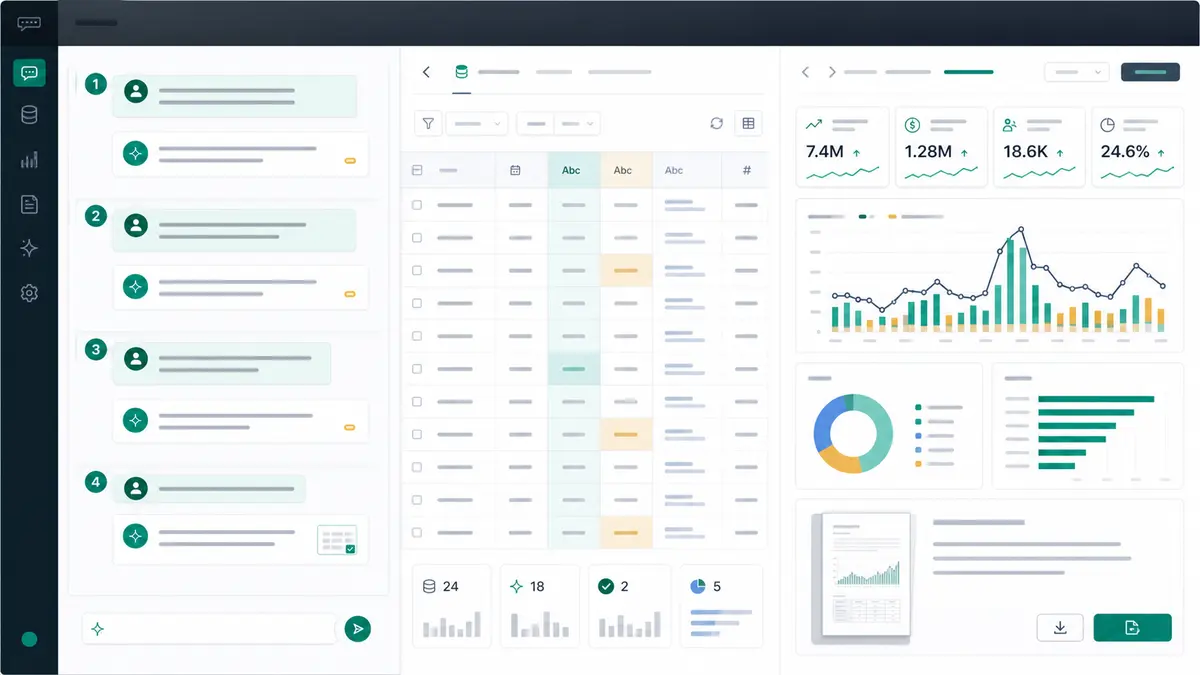
That is how Anomaly AI does things. We are not about replacing analysts. We've built a world where human and LLM coexist in close loops. The AI generates code to execute some analysis. The human reviews that code, ensures it makes sense. The code is executed and produces results. The human interprets the results with the aid of domain knowledge. The AI informs the human what to look at next. And the cycle repeats.
This collaborative method does several things at once. It keeps the human engaged throughout the process, so you don't end up losing the domain experience and context that the machine lacks. It builds in checkpoints where you can catch hallucination or mistakes before they propagate. There is code to support each analysis that you can check and re-run. And most of all, the human remains in command. The analyst controls; the AI is a helper.
This reduces hallucinations significantly. When there's human oversight at every step, when every analysis is verified by someone who understands the domain, the chances of nonsense getting through drop dramatically. You get better insights because you're combining human domain knowledge with AI's ability to handle the mechanical work.
Why the Excel Copilot Falls Short
That tells you something about current "AI-enabled" products. When you look at Excel Copilot or SQL assistants laid over top of current systems, you are looking at individuals sticking an engine on a horse wagon. The horse is no longer needed. You could construct a car.
Excel with its grid interface, invisible formulas, pivot tables, chart wizards—all that complexity is there because we needed a formal way to deal with tables when programming was esoteric and computing power was costly. Power BI and Tableau are identical. They're visual programming languages because we couldn't simply say what we wanted in natural language.
But if one can input "show me monthly revenue trends by product category with year-over-year comparisons" and produce the SQL query, the data manipulations, and the visualization code within seconds—why the intricate interface? The entire cumbersome GUI layer between your idea and the execution becomes superfluous.
This isn't about making Excel less cluttered. It's about acknowledging that maybe Excel is becoming outdated. When you can define what you want in natural language, get it translated to code, scrutinize the code, and be shown the outcome—you've removed all the intermediary interfaces.
The Road Ahead
The future isn't people or computers. It's people with computers, each doing what they do best. Code generation, translating what you desire into executable code, boring data manipulation? LLMs shine here. Understanding the domain, knowing what questions really count, putting results in context? Humans do this best.
By keeping the LLMs working on writing code, and keeping the human actively involved in each step, you end up with systems that are stronger and more trustworthy than either could be by itself. The code offers verification—you can clearly see what happened. The human offers expertise—you can recognize right away if something doesn't look right. That is why everything within Anomaly AI is grounded in code. Every observation is substantiated with code. Every analysis can be viewed, interpreted. The AI will never provide you with black-box answers. The AI will present you with transparent processes that you can trust because you can see precisely what the analysis has occurred. The revolution isn't that AI can think for us. It's that AI can eliminate all the mechanical overhead that's always stood between our questions and our insights, while keeping us engaged in the actual analysis. That's the future worth building.
Try Anomaly AI free to see what code-first, SQL-transparent analysis feels like on your own dataset.