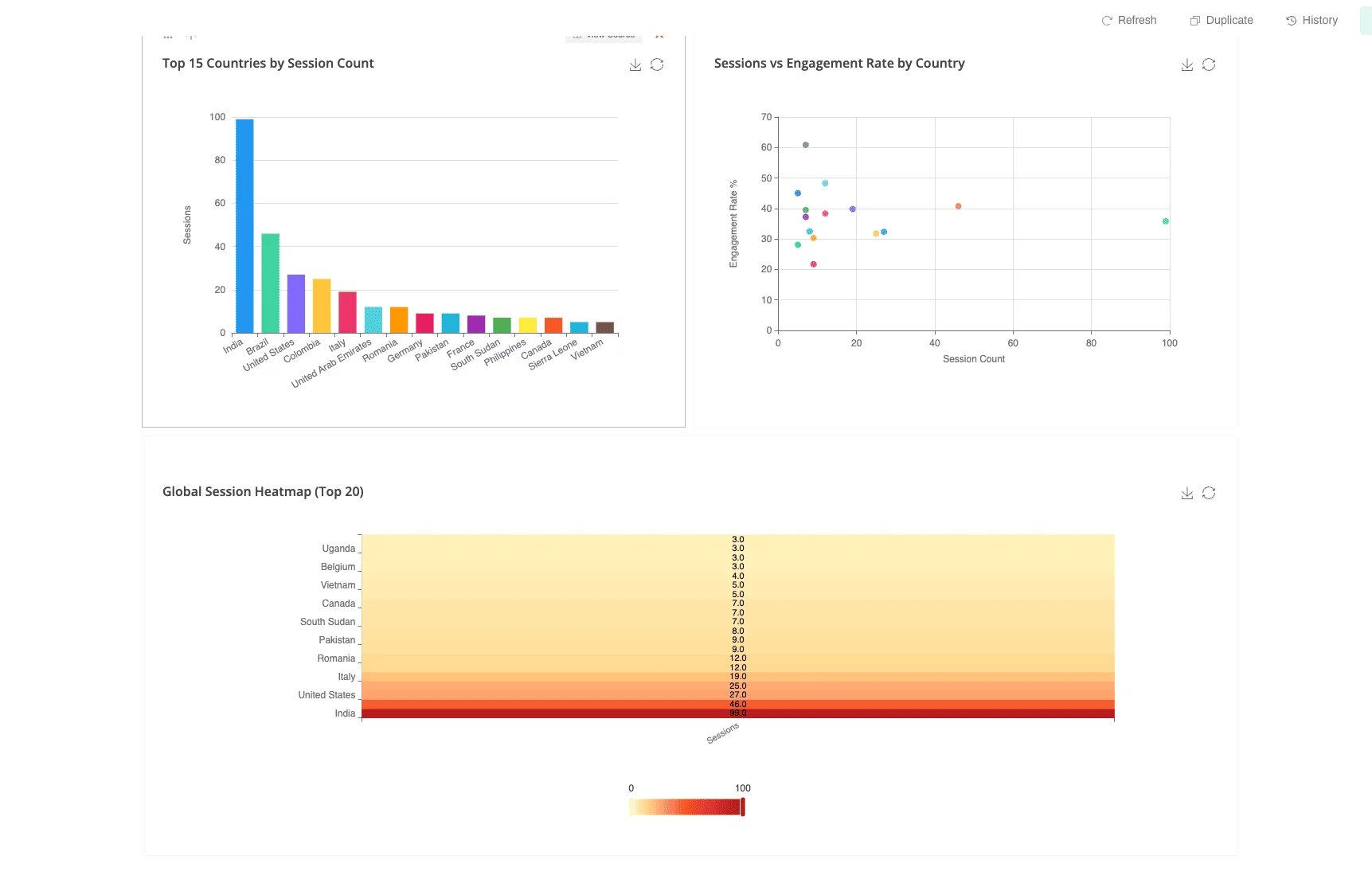
Google BigQuery has evolved from a simple cloud data warehouse into a comprehensive data analytics platform that processes over 110 terabytes of data per second across Google's global infrastructure. As organizations increasingly move analytics to the cloud, understanding BigQuery's capabilities, cost optimization strategies, and best practices has become critical for data-driven success.
After architecting BigQuery implementations processing petabytes of data for Fortune 500 companies, I've learned that BigQuery's true power lies not just in its raw performance, but in knowing how to leverage its unique features while avoiding costly pitfalls.
In this comprehensive guide, I'll break down everything you need to know about using Google BigQuery for data analytics in 2026—from core architecture to advanced features like BigQuery ML, cost optimization strategies that can meaningfully reduce query costs when applied correctly, and migration best practices based on real implementations.
What is Google BigQuery?
Google BigQuery is a fully managed, serverless cloud data warehouse designed for big data analytics. Unlike traditional databases that require infrastructure management, BigQuery separates storage from compute, enabling:
- Serverless Architecture: Zero infrastructure management—no clusters, nodes, or configuration tuning
- Automatic Scaling: Query performance scales linearly with data volume
- Columnar Storage: Optimized for analytical queries scanning billions of rows
- Standard SQL: ANSI SQL 2011 compliant with extensions for analytics
- Built-in ML: Train machine learning models using SQL (BigQuery ML)
According to Google Cloud documentation, BigQuery processes exabytes of data daily, providing sub-second query response times for interactive analytics.
Why BigQuery Dominates Cloud Analytics
BigQuery's architecture delivers three key advantages over traditional data warehouses:
- Separation of Storage and Compute: Scale each independently, paying only for what you use
- Distributed Processing: Queries automatically parallelize across thousands of nodes
- No Maintenance Windows: Upgrades, backups, and optimization happen transparently
Real-World Performance: In TPC-DS benchmarks, BigQuery achieved a 20.2-second geometric mean query time on 10TB datasets, according to industry benchmark studies.
BigQuery 2026: Latest Features and Capabilities
According to BigQuery release notes, Google has introduced several transformative features in 2026:
1. Gemini AI Integration (Generally Available 2026)
Gemini Cloud Assist: Generate SQL queries using natural language and apply them directly to the query editor. This feature represents BigQuery's evolution toward conversational analytics—users can ask questions in plain English and receive optimized SQL.
- Use Case: Business analysts without SQL expertise can now query data independently
- Status: Generally Available
- Impact: Democratizes data access beyond technical teams
2. Google Analytics 4 Integration (Enhanced 2026)
The BigQuery Data Transfer Service now supports transferring GA4 reporting data, including custom reports, directly into BigQuery for advanced analysis.
- Benefit: Combine marketing data with sales, CRM, and operational datasets
- Status: Generally Available
- Expert Tip: I've helped clients uncover customer journey insights by joining GA4 events with Salesforce data in BigQuery—analysis impossible in GA4's standard interface
3. Workload Management Autoscaler (Enhanced 2026)
Enhanced autoscaling dynamically adjusts compute resources based on query demand, optimizing both performance and cost.
- Benefit: Automatically scale slots during peak loads, reduce during quiet periods
- Cost Impact: Can reduce compute costs by 30-50% for variable workloads
- Status: Generally Available
4. BigQuery ML Model Monitoring (Enhanced 2026)
Visualize model monitoring metrics through charts and graphs, enabling proactive model performance management.
- Key Metrics: Prediction drift, feature distribution changes, model accuracy over time
- Status: Generally Available
- Use Case: Detect when ML models need retraining before performance degrades
5. Multi-Cloud Support with BigQuery Omni
According to Google Cloud's announcement, BigQuery Omni enables cross-cloud analytics on data stored in AWS and Azure without data movement.
- Supported Regions:
- AWS: US East, US West, Seoul, Sydney, Ireland, Frankfurt
- Azure: East US 2
- Cross-Cloud Joins: Join GCP, AWS, and Azure data in a single query
- Benefit: Break down data silos without costly ETL pipelines
BigQuery ML: Machine Learning Without Python
BigQuery ML democratizes machine learning by enabling data analysts to build ML models using standard SQL. According to BigQuery ML documentation, this eliminates the need to move data between systems or learn Python/R.
Supported Model Types
BigQuery ML supports a comprehensive range of models for various data analytics use cases:
- Linear Regression: Forecast sales, predict revenue
- Logistic Regression: Customer churn prediction, fraud detection
- K-Means Clustering: Customer segmentation, anomaly detection
- Time Series (ARIMA): Demand forecasting, trend analysis
- Deep Neural Networks: Complex pattern recognition
- XGBoost: High-accuracy classification and regression
- AutoML Tables: Automated model selection and hyperparameter tuning
- Import Models: Use TensorFlow, PyTorch, or scikit-learn models
Creating a BigQuery ML Model: Step-by-Step
Example: Customer Churn Prediction
1. Create the Model:
CREATE MODEL `your_dataset.churn_model`
OPTIONS(
model_type='LOGISTIC_REG',
input_label_cols=['churned']
) AS
SELECT
customer_tenure_months,
monthly_charges,
total_charges,
num_support_tickets,
contract_type,
churned
FROM
`your_project.your_dataset.customer_data`
WHERE
training_date < '2026-01-01';
2. Evaluate Model Performance:
SELECT
roc_auc,
accuracy,
precision,
recall
FROM
ML.EVALUATE(MODEL `your_dataset.churn_model`, (
SELECT
customer_tenure_months,
monthly_charges,
total_charges,
num_support_tickets,
contract_type,
churned
FROM
`your_project.your_dataset.customer_data`
WHERE
training_date >= '2026-01-01'
));
3. Generate Predictions:
SELECT
customer_id,
predicted_churned,
predicted_churned_probs[OFFSET(1)].prob AS churn_probability
FROM
ML.PREDICT(MODEL `your_dataset.churn_model`, (
SELECT
customer_id,
customer_tenure_months,
monthly_charges,
total_charges,
num_support_tickets,
contract_type
FROM
`your_project.your_dataset.active_customers`
))
WHERE
predicted_churned_probs[OFFSET(1)].prob > 0.7
ORDER BY churn_probability DESC;
BigQuery ML vs Traditional ML Pipelines
Traditional Approach:
- Export data from warehouse → Load into Python environment → Clean/transform → Train model → Deploy to production → Maintain infrastructure
- Timeline: 2-4 weeks for simple models
- Skills Required: Python, scikit-learn/TensorFlow, MLOps
BigQuery ML Approach:
- Write SQL query → Model trains automatically → Predictions available via SQL
- Timeline: Hours to days
- Skills Required: SQL (that's it)
Hypothetical example: a retail team using BigQuery ML can often get to a working customer lifetime value (CLV) prediction model in days rather than the weeks a separate Python data-science workflow would require. The SQL-based approach lets marketing analysts iterate on features directly without waiting for data science resources.
BigQuery Pricing: Understanding and Optimization
BigQuery's pricing model is both its greatest strength and biggest trap for the unprepared. According to pricing research, organizations can reduce costs by 60-80% through proper optimization.
Pricing Components
1. Storage Costs:
- Active Storage: $0.02 per GB per month ($20 per TB)
- Long-Term Storage: $0.01 per GB per month ($10 per TB)
- Automatically applied to tables/partitions unchanged for 90+ days
- 50% automatic savings without any configuration
2. Compute Costs (Two Models):
On-Demand Pricing:
- $6.25 per TB of data processed (updated from $5 in early 2024)
- First 1 TB per month free
- Best For: Unpredictable, intermittent workloads
- Cost Control: Use query cost estimator before running queries
Capacity Pricing (BigQuery Editions):
- Standard Edition: Starting at $2,000/month for 100 slots (baseline)
- Enterprise Edition: Enhanced autoscaling, longer query timeouts
- Enterprise Plus: Advanced security, data governance, SLA guarantees
- Best For: Consistent, high-volume query workloads
Cost Comparison Example:
Processing 50 TB of data monthly:
- On-Demand: (50 TB - 1 TB free) × $6.25 = $306.25/month
- Standard Slots: $2,000/month (breakeven at ~320 TB processed)
Cost Optimization Strategies
Based on Google Cloud best practices and real-world implementations:
1. Partitioning and Clustering (40-80% Cost Reduction)
Partitioning: Divide tables into segments (usually by date) so queries only scan relevant partitions.
CREATE TABLE `project.dataset.sales`
PARTITION BY DATE(order_date)
CLUSTER BY customer_id, product_category
AS SELECT * FROM `project.dataset.legacy_sales`;
Impact: A query filtering on order_date = '2026-01-15' scans only one day's partition instead of the entire table.
Before: Scanning 10 TB historical table = $62.50/query
After: Scanning 50 GB daily partition = $0.31/query
Savings: 99.5% per query
Clustering: Organize data within partitions based on frequently filtered columns.
- Queries filtering on clustered columns scan even less data
- Automatic maintenance (no rebuild required)
- Particularly effective for high-cardinality columns (customer IDs, product SKUs)
2. Materialized Views (40-80% Cost Reduction)
According to optimization studies, materialized views can reduce costs by 40-80% for complex, frequently-run queries.
CREATE MATERIALIZED VIEW `project.dataset.daily_revenue_by_category`
AS
SELECT
DATE(order_date) as order_day,
product_category,
SUM(revenue) as total_revenue,
COUNT(DISTINCT customer_id) as unique_customers
FROM
`project.dataset.sales`
GROUP BY order_day, product_category;
Benefit: Precomputed aggregations stored and automatically refreshed. Queries against the view are essentially free (only query the small materialized result, not the raw data).
3. Avoid SELECT * Queries
BigQuery's columnar storage means you're charged for columns scanned, not rows.
Bad:
SELECT * FROM `project.dataset.web_analytics`
WHERE visit_date = '2026-01-15';
-- Scans all 50 columns = $$$
Good:
SELECT
visitor_id,
page_views,
conversion_flag
FROM `project.dataset.web_analytics`
WHERE visit_date = '2026-01-15';
-- Scans only 3 columns = $ (80%+ savings)
4. Use Query Cost Estimator
BigQuery's UI shows estimated bytes scanned before running queries. Use this to avoid expensive surprises.
Expert Tip: Set up billing alerts at 50%, 75%, and 90% of monthly budget. Unoptimized dashboards that scan full tables on every refresh are the most common source of surprise BigQuery bills — a single dashboard refreshing hourly against a large table can burn through a budget fast.
5. Implement Table Expiration
Set expiration times for temporary tables and staging datasets to avoid accumulating storage costs.
ALTER TABLE `project.dataset.temp_analysis`
SET OPTIONS (
expiration_timestamp=TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 7 DAY)
);
Migrating to BigQuery: Best Practices
According to Google Cloud migration documentation, successful BigQuery migrations follow a phased approach rather than "big bang" cutover.
Migration Strategy Framework
Phase 1: Assessment & Planning (2-4 weeks)
- Inventory Current State: Document all data sources, pipelines, reports, dashboards
- Identify Dependencies: Map upstream/downstream systems
- Categorize Workloads: Batch vs real-time, critical vs nice-to-have
- Estimate Costs: Use BigQuery pricing calculator with actual query patterns
- Define Success Metrics: Performance benchmarks, cost targets, adoption rates
Phase 2: Proof of Concept (4-6 weeks)
- Select Pilot Use Case: Choose non-critical but representative workload
- Migrate Sample Data: Start with 1-3 months of historical data
- Rewrite Key Queries: Optimize for BigQuery (leverage partitioning, clustering)
- Validate Results: Compare query outputs between source and BigQuery
- Measure Performance: Benchmark query times, costs, user satisfaction
Phase 3: Iterative Migration (3-6 months)
- Migrate in Waves: Start with less critical datasets
- Optimize Schema: Denormalize using nested/repeated fields where appropriate
- Automate Data Pipelines: Use BigQuery Data Transfer Service, Cloud Functions, or Dataflow
- Parallel Run: Run old and new systems simultaneously for validation
- Train Users: SQL workshops, best practices documentation, office hours
Phase 4: Optimization & Governance (Ongoing)
- Monitor Costs: Weekly cost reviews, identify expensive queries
- Implement Governance: Data catalog, access controls, audit logging
- Continuous Improvement: Regular query optimization reviews
Common Migration Pitfalls to Avoid
1. Direct SQL Translation Without Optimization
Don't just copy-paste existing SQL. BigQuery has unique optimization opportunities:
- ❌ Bad: Recreate star schema with 15 joins (optimized for OLTP databases)
- ✅ Good: Denormalize into wide tables with nested fields (optimized for BigQuery)
2. Ignoring Data Validation
According to migration best practices research, automated data validation is critical:
- Compare row counts, sum totals, unique values between source and target
- Run identical queries on both systems and diff results
- Schedule ongoing reconciliation jobs during parallel run phase
3. Underestimating Training Needs
BigQuery's serverless model is fundamentally different from traditional databases:
- No indexes to manage (partition/cluster instead)
- No COMMIT/ROLLBACK (all writes are transactional but no multi-statement transactions)
- Different performance tuning mindset (think about bytes scanned, not index seeks)
Real-World Case Study: A financial services client migrated 15 TB from Oracle to BigQuery over 4 months. The migration succeeded because they:
- Started with 3 low-risk reports as POC
- Ran parallel systems for 6 weeks during validation
- Trained 25 analysts through weekly "BigQuery office hours"
- Result: 85% faster query performance, 60% cost reduction vs Oracle licensing + infrastructure
BigQuery BI Engine and Visualization Integration
BigQuery BI Engine is an in-memory analysis service that accelerates visualization dashboards. According to BI Engine integration guides, it provides sub-second query response times for interactive dashboards.
BI Engine Benefits
- Performance: Caches frequently accessed data in memory for instant queries
- Cost Efficiency: 1 GB free per Looker Studio user; additional capacity ~$30/GB/month
- Seamless Integration: Works automatically with Looker Studio, Tableau, Power BI
Setting Up BI Engine
1. Enable BI Engine:
- Navigate to BigQuery in Google Cloud Console
- Select project and dataset
- Click "BI Engine" and configure memory capacity (start with 10-50 GB)
2. Optimize for BI Engine:
- Create aggregated tables or materialized views for dashboard queries
- Use partitioning/clustering on dashboard data sources
- Keep frequently accessed data under BI Engine capacity
Looker Studio Integration
Looker Studio (formerly Google Data Studio) provides native BigQuery connectivity:
- Direct connection to BigQuery datasets (no data export required)
- Live queries or extract mode for faster load times
- Automatic BI Engine acceleration for supported queries
- Custom SQL support for complex transformations
Hypothetical example: an e-commerce team builds executive dashboards over hundreds of gigabytes of daily transaction data. Before BI Engine, dashboard queries scan the raw table and load times stretch into seconds. After enabling BI Engine and caching the hot dimensions, load times drop sharply — often to sub-second for the common queries — at the cost of the reserved BI Engine capacity. Exact numbers depend on dimension cardinality, query selectivity, and how much of the working set fits in the reservation.
Security and Compliance Features
According to BigQuery security documentation, the platform provides enterprise-grade security across multiple layers:
Encryption
1. Encryption at Rest (Automatic):
- AES-256 encryption for all data automatically
- Google-managed keys by default (no configuration required)
- Customer-Managed Encryption Keys (CMEK) available via Cloud KMS
- Client-side encryption option for additional control
2. Encryption in Transit:
- TLS 1.3 for all data transmission
- Encrypted within Google's internal networks
3. Column-Level Encryption:
- SQL functions for encrypting specific columns (PII, PHI)
- Support for AES-GCM and AES-SIV algorithms
- Cloud KMS integration for key management
Access Control
1. Identity and Access Management (IAM):
- Granular permissions at project, dataset, table, and column levels
- Predefined roles (BigQuery Admin, Data Editor, Data Viewer)
- Custom roles for specific organizational needs
2. Dynamic Data Masking:
- Obfuscate sensitive data at query time based on user roles
- No data duplication required
- Compliant with GDPR, HIPAA, PCI DSS requirements
3. VPC Service Controls:
- Define security perimeter around BigQuery resources
- Prevent data exfiltration
- Restrict access based on source IP or identity
Compliance Certifications
BigQuery holds major compliance certifications:
- ✅ SOC 2/SOC 3
- ✅ ISO 27001, ISO 27017, ISO 27018
- ✅ HIPAA (with BAA)
- ✅ PCI DSS
- ✅ FedRAMP (for government workloads)
- ✅ GDPR compliant
Expert Tip: For HIPAA compliance, you MUST sign a Business Associate Agreement (BAA) with Google before loading PHI into BigQuery. The platform is HIPAA-capable, but compliance requires proper configuration and legal agreements.
Real-World BigQuery Use Cases
Based on implementations across industries, here are proven BigQuery data analytics use cases:
The three patterns below are illustrative, not specific customer engagements.
1. E-Commerce: Real-Time Product Recommendations (Hypothetical)
Challenge: Process tens of millions of daily clickstream events to power product recommendations.
Solution pattern:
- Stream clickstream data to BigQuery via Pub/Sub + Dataflow
- BigQuery ML collaborative filtering model for recommendations
- BI Engine-powered dashboards for the merchandising team
What this pattern tends to unlock: lower recommendation latency and simpler infrastructure than a self-managed Hadoop cluster. Actual conversion lift and infrastructure-cost delta depend on traffic, catalog size, and the baseline you're replacing.
2. Healthcare: Population Health Analytics (Hypothetical)
Challenge: Analyze large volumes of EHR data across a patient population for risk stratification.
Solution pattern:
- Federated queries connecting EHR systems, claims data, and pharmacy records
- BigQuery ML logistic regression for hospital readmission prediction
- Column-level encryption for PHI compliance
What this pattern tends to unlock: HIPAA-compliant analytics without moving data between silos, and care-manager access to updated risk scores through Looker Studio. Clinical outcomes depend on model quality, intervention design, and adoption — treat any specific readmission-reduction figure from a vendor case study as upper-bound, not baseline.
3. Financial Services: Fraud Detection (Hypothetical)
Challenge: Detect fraudulent transactions in near-real-time across millions of daily transactions.
Solution pattern:
- Streaming inserts for real-time transaction data
- BigQuery ML XGBoost model for fraud classification
- Materialized views for fraud pattern analysis
What this pattern tends to unlock: low-latency fraud scoring at scale and fraud-loss reduction versus rule-based systems. Achieved accuracy varies by transaction mix, label quality, and feature engineering.
BigQuery vs Alternatives
How does BigQuery compare to other big data analytics tools?
BigQuery vs Snowflake
- Performance: BigQuery and Snowflake trade the lead depending on workload — BigQuery tends to win on very large table scans, Snowflake tends to win on complex joins and high-concurrency workloads. Benchmark on your own queries; published deltas vary widely by test setup. See our detailed comparison.
- Pricing: BigQuery better for unpredictable workloads; Snowflake better for high-concurrency
- ML Capabilities: BigQuery ML more mature; Snowflake ML in preview
- Multi-Cloud: Both support multi-cloud (BigQuery Omni vs Snowflake's native multi-cloud)
BigQuery vs Traditional Data Warehouses
- Scalability: BigQuery handles petabytes without performance tuning; traditional warehouses require capacity planning
- Operational Overhead: BigQuery zero maintenance; traditional warehouses require DBAs
- Cost Model: BigQuery pay-per-query; traditional warehouses fixed licensing + hardware
- Time-to-Value: BigQuery minutes to start; traditional warehouses weeks to provision
The AI-Powered Alternative to BigQuery
While BigQuery excels at data analytics for technical teams, it still requires SQL expertise. For organizations seeking analytics without the learning curve, AI-powered platforms offer a compelling alternative.
Anomaly AI provides an AI data analyst agent that delivers BigQuery-like insights through natural language—no SQL writing required, with the generated SQL available for review:
- Natural Language Queries: "Show revenue trends by region" instead of writing SQL
- Automatic Optimization: AI generates optimized queries automatically
- Self-Service Analytics: Business users get insights without data team bottlenecks
- Fraction of Complexity: Minutes to start vs weeks learning BigQuery
When to Choose BigQuery: Technical teams, complex analytics, existing GCP infrastructure
When to Choose AI Platforms: Non-technical users, self-service analytics, rapid deployment
Many organizations use both—BigQuery for data engineering and warehousing, AI platforms for business user analytics. Learn more in our guide on AI data analysis trends.
Conclusion: Maximizing BigQuery for Data Analytics
Google BigQuery has matured into a comprehensive data analytics platform that combines the power of a traditional data warehouse with modern cloud-native architecture, built-in ML, and serverless convenience.
Key Takeaways:
- Start Smart: Use partitioning, clustering, and materialized views from day one — they're the highest-leverage cost-reduction patterns for most dashboard and analytics workloads.
- Leverage BigQuery ML: Build ML models in SQL without Python expertise
- Optimize Continuously: Monitor costs weekly, identify expensive queries, refactor
- Migrate Iteratively: Phased approach with POC, parallel run, and continuous validation
- Integrate BI Engine: Sub-second dashboard performance for better user experience
- Implement Governance: Security, access control, and compliance from the start
For organizations evaluating big data analytics tools, BigQuery offers a compelling combination of performance, scalability, and ease of use—particularly for teams already in the Google Cloud ecosystem or those prioritizing serverless architecture.
Ready to explore analytics without SQL complexity? Connect your BigQuery data to Anomaly AI and get insights through natural language queries.
Related Reading: